Node failure resiliency for Uintah without checkpointing
Journal Article
·
· Concurrency and Computation. Practice and Experience
- Univ. of Utah, Salt Lake City, UT (United States); University of Utah
- Univ. of Utah, Salt Lake City, UT (United States)
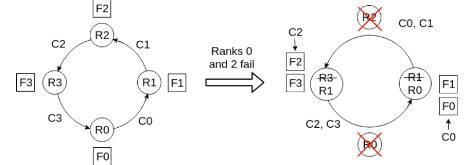
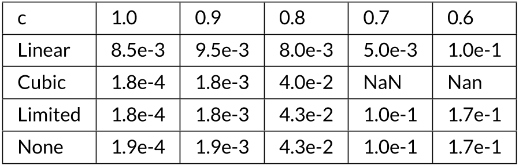
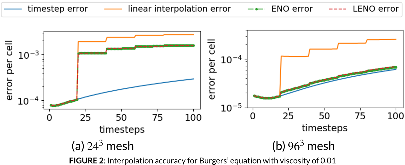
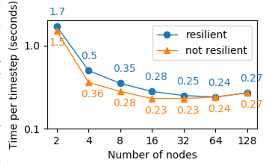
The frequency of failures in upcoming exascale supercomputers may well be greater than at present due to many-core architectures if component failure rates remain unchanged. This potential increase in failure frequency coupled with I/O challenges at exascale may prove problematic for current resiliency approaches such as checkpoint restarting, although the use of fast intermediate memory may help. Algorithm-Based Fault Tolerance (ABFT) using Adaptive Mesh Refinement (AMR) is one resiliency approach used to address these challenges. For adaptive mesh codes, a coarse mesh version of the solu- tion may be used to restore the fine mesh solution. This paper addresses the implementation of the ABFT approach within the Uintah software framework: both at a software level within Uintah and in the data reconstruction method used for the recovery of lost data. This method has two problems: inaccuracies introduced during the reconstruction propagate forward in time, and the physical consistency of variables such as positivity or boundedness may be violated during interpolation. These challenges can be addressed by the combination of two techniques: 1. a fault-tolerant MPI implementation to recover from runtime node failures, and 2. high-order interpolation schemes to preserve the physical solution and reconstruct lost data. Here, the approach considered here uses a "Limited Essentially Non-Oscillatory" (LENO) scheme along with AMR to rebuild the lost data without checkpointing using Uintah. Experiments were carried out using a fault-tolerant MPI - ULFM to recover from runtime failure, and LENO to recover data on patches belonging to failed ranks, while the simulation was continued to the end. Results show that this ABFT approach is up to 10x faster than the traditional checkpointing method. The new interpolation approach is more accurate than linear interpolation and not subject to the overshoots found in other interpolation methods.
- Research Organization:
- Univ. of Utah, Salt Lake City, UT (United States)
- Sponsoring Organization:
- National Science Foundation; USDOE National Nuclear Security Administration (NNSA)
- Grant/Contract Number:
- NA0002375
- OSTI ID:
- 1637354
- Journal Information:
- Concurrency and Computation. Practice and Experience, Journal Name: Concurrency and Computation. Practice and Experience Journal Issue: 20 Vol. 31; ISSN 1532-0626
- Publisher:
- WileyCopyright Statement
- Country of Publication:
- United States
- Language:
- English


Similar Records
Supporting the Development of Resilient Message Passing Applications using Simulation
The Impact of a Fault Tolerant MPI on Scalable Systems Services and Applications
Evaluating Online Global Recovery with Fenix Using Application-Aware In-Memory Checkpointing Techniques
Conference
·
Tue Dec 31 23:00:00 EST 2013
·
OSTI ID:1131524
The Impact of a Fault Tolerant MPI on Scalable Systems Services and Applications
Conference
·
Sat Dec 31 23:00:00 EST 2011
·
OSTI ID:1049912
Evaluating Online Global Recovery with Fenix Using Application-Aware In-Memory Checkpointing Techniques
Conference
·
Mon Aug 01 00:00:00 EDT 2016
·
OSTI ID:1567425