Panda: A Compiler Framework for Concurrent CPU $$+$$ GPU Execution of 3D Stencil Computations on GPU-accelerated Supercomputers
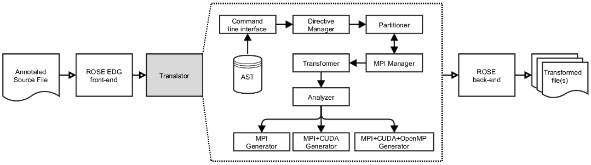
We present a new compiler framework for truly heterogeneous 3D stencil computation on GPU clusters. Our framework consists of a simple directive-based programming model and a tightly integrated source-to-source compiler. Annotated with a small number of directives, sequential stencil C codes can be automatically parallelized for large-scale GPU clusters. The most distinctive feature of the compiler is its capability to generate hybrid MPI$$+$$ CUDA$$+$$ OpenMP code that uses concurrent CPU$$+$$ GPU computing to unleash the full potential of powerful GPU clusters. The auto-generated hybrid codes hide the overhead of various data motion by overlapping them with computation. Test results on the Titan supercomputer and the Wilkes cluster show that auto-translated codes can achieve about 90 % of the performance of highly optimized handwritten codes, for both a simple stencil benchmark and a real-world application in cardiac modeling. The user-friendliness and performance of our domain-specific compiler framework allow harnessing the full power of GPU-accelerated supercomputing without painstaking coding effort.
- Research Organization:
- Lawrence Berkeley National Laboratory (LBNL), Berkeley, CA (United States)
- Sponsoring Organization:
- USDOE Office of Science (SC)
- Grant/Contract Number:
- AC02-05CH11231
- OSTI ID:
- 1525220
- Journal Information:
- International Journal of Parallel Programming, Vol. 45, Issue 3; ISSN 0885-7458
- Publisher:
- SpringerCopyright Statement
- Country of Publication:
- United States
- Language:
- English
Web of Science
An auto-tuning framework for parallel multicore stencil computations
|
conference | April 2010 |
High-performance code generation for stencil computations on GPU architectures
|
conference | January 2012 |
Mint: realizing CUDA performance in 3D stencil methods with annotated C
|
conference | January 2011 |
A Survey of CPU-GPU Heterogeneous Computing Techniques
|
journal | July 2015 |
CPU+GPU Programming of Stencil Computations for Resource-Efficient Use of GPU Clusters
|
conference | October 2015 |
Physis: an implicitly parallel programming model for stencil computations on large-scale GPU-accelerated supercomputers
|
conference | January 2011 |
Halide: a language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines
|
conference | January 2013 |
PATUS: A Code Generation and Autotuning Framework for Parallel Iterative Stencil Computations on Modern Microarchitectures
|
conference | May 2011 |
A Study on Balancing Parallelism, Data Locality, and Recomputation in Existing PDE Solvers
|
conference | November 2014 |
Towards automatic translation of OpenMP to MPI
|
conference | January 2005 |
Understanding stencil code performance on multicore architectures
|
conference | January 2011 |
Auto-generation and auto-tuning of 3D stencil codes on GPU clusters
|
conference | January 2012 |
Early evaluation of directive-based GPU programming models for productive exascale computing
|
conference | November 2012 |
Abstract Machine Models and Proxy Architectures for Exascale Computing
|
conference | November 2014 |
Distributed memory code generation for mixed Irregular/Regular computations
|
conference | January 2015 |
PARTANS: An autotuning framework for stencil computation on multi-GPU systems
|
journal | January 2013 |
Tuned and wildly asynchronous stencil kernels for hybrid CPU/GPU systems
|
conference | January 2009 |
OpenMPC: Extended OpenMP Programming and Tuning for GPUs
|
conference | November 2010 |
High Performance Stencil Code Algorithms for GPGPUs
|
journal | January 2011 |
STELLA: a domain-specific tool for structured grid methods in weather and climate models
|
conference | January 2015 |
Peta-scale phase-field simulation for dendritic solidification on the TSUBAME 2.0 supercomputer
|
conference | January 2011 |
SnuCL: an OpenCL framework for heterogeneous CPU/GPU clusters
|
conference | January 2012 |
Hybrid Hexagonal/Classical Tiling for GPUs
|
conference | January 2014 |
Scalable Heterogeneous CPU-GPU Computations for Unstructured Tetrahedral Meshes
|
journal | July 2015 |
Optimization of geometric multigrid for emerging multi- and manycore processors
|
conference | November 2012 |
On the GPU Performance of 3D Stencil Computations Implemented in OpenCL
|
book | January 2013 |
Roofline: an insightful visual performance model for multicore architectures
|
journal | April 2009 |
Hybridizing S3D into an Exascale application using OpenACC: An approach for moving to multi-petaflops and beyond
|
conference | November 2012 |
High-Productivity Framework on GPU-Rich Supercomputers for Operational Weather Prediction Code ASUCA
|
conference | November 2014 |
| Domain-Specific Multi-Level IR Rewriting for GPU | preprint | January 2020 |





Similar Records
Compiler-based code generation and autotuning for geometric multigrid on GPU-accelerated supercomputers
Multi-GPU Implementation of a 3D Finite Difference Time Domain Earthquake Code on Heterogeneous Supercomputers