
Panda: A Compiler Framework for Concurrent CPU $$+$$ GPU Execution of 3D Stencil Computations on GPU-accelerated Supercomputers
Abstract
We present a new compiler framework for truly heterogeneous 3D stencil computation on GPU clusters. Our framework consists of a simple directive-based programming model and a tightly integrated source-to-source compiler. Annotated with a small number of directives, sequential stencil C codes can be automatically parallelized for large-scale GPU clusters. The most distinctive feature of the compiler is its capability to generate hybrid MPI$$+$$ CUDA$$+$$ OpenMP code that uses concurrent CPU$$+$$ GPU computing to unleash the full potential of powerful GPU clusters. The auto-generated hybrid codes hide the overhead of various data motion by overlapping them with computation. Test results on the Titan supercomputer and the Wilkes cluster show that auto-translated codes can achieve about 90 % of the performance of highly optimized handwritten codes, for both a simple stencil benchmark and a real-world application in cardiac modeling. The user-friendliness and performance of our domain-specific compiler framework allow harnessing the full power of GPU-accelerated supercomputing without painstaking coding effort.
- Authors:
-
 [1];
[1];
- Simula Research Lab., Oslo (Norway); Univ. of Oslo (Norway)
- Univ. of California, San Diego, CA (United States)
- Publication Date:
- Research Org.:
- Lawrence Berkeley National Laboratory (LBNL), Berkeley, CA (United States)
- Sponsoring Org.:
- USDOE Office of Science (SC)
- OSTI Identifier:
- 1525220
- Grant/Contract Number:
- AC02-05CH11231
- Resource Type:
- Accepted Manuscript
- Journal Name:
- International Journal of Parallel Programming
- Additional Journal Information:
- Journal Volume: 45; Journal Issue: 3; Journal ID: ISSN 0885-7458
- Publisher:
- Springer
- Country of Publication:
- United States
- Language:
- English
- Subject:
- 97 MATHEMATICS AND COMPUTING
Citation Formats
Sourouri, Mohammed, Baden, Scott B., and Cai, Xing. Panda: A Compiler Framework for Concurrent CPU $+$ GPU Execution of 3D Stencil Computations on GPU-accelerated Supercomputers. United States: N. p., 2016.
Web. doi:10.1007/s10766-016-0454-1.
Sourouri, Mohammed, Baden, Scott B., & Cai, Xing. Panda: A Compiler Framework for Concurrent CPU $+$ GPU Execution of 3D Stencil Computations on GPU-accelerated Supercomputers. United States. https://doi.org/10.1007/s10766-016-0454-1
Sourouri, Mohammed, Baden, Scott B., and Cai, Xing. Wed .
"Panda: A Compiler Framework for Concurrent CPU $+$ GPU Execution of 3D Stencil Computations on GPU-accelerated Supercomputers". United States. https://doi.org/10.1007/s10766-016-0454-1. https://www.osti.gov/servlets/purl/1525220.
@article{osti_1525220,
title = {Panda: A Compiler Framework for Concurrent CPU $+$ GPU Execution of 3D Stencil Computations on GPU-accelerated Supercomputers},
author = {Sourouri, Mohammed and Baden, Scott B. and Cai, Xing},
abstractNote = {We present a new compiler framework for truly heterogeneous 3D stencil computation on GPU clusters. Our framework consists of a simple directive-based programming model and a tightly integrated source-to-source compiler. Annotated with a small number of directives, sequential stencil C codes can be automatically parallelized for large-scale GPU clusters. The most distinctive feature of the compiler is its capability to generate hybrid MPI$+$ CUDA$+$ OpenMP code that uses concurrent CPU$+$ GPU computing to unleash the full potential of powerful GPU clusters. The auto-generated hybrid codes hide the overhead of various data motion by overlapping them with computation. Test results on the Titan supercomputer and the Wilkes cluster show that auto-translated codes can achieve about 90 % of the performance of highly optimized handwritten codes, for both a simple stencil benchmark and a real-world application in cardiac modeling. The user-friendliness and performance of our domain-specific compiler framework allow harnessing the full power of GPU-accelerated supercomputing without painstaking coding effort.},
doi = {10.1007/s10766-016-0454-1},
journal = {International Journal of Parallel Programming},
number = 3,
volume = 45,
place = {United States},
year = {Wed Oct 05 00:00:00 EDT 2016},
month = {Wed Oct 05 00:00:00 EDT 2016}
}
 Search WorldCat to find libraries that may hold this journal
Search WorldCat to find libraries that may hold this journalWeb of Science
Figures / Tables:
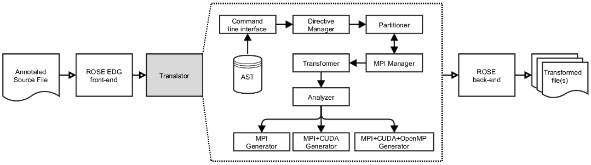 Fig. 1: An architectural view of the Panda source-to-source compiler, which adopts a modular design. Each module may consist of numerous sub-modules, but for brevity, only the most important sub-modules are depicted.
Fig. 1: An architectural view of the Panda source-to-source compiler, which adopts a modular design. Each module may consist of numerous sub-modules, but for brevity, only the most important sub-modules are depicted.
Works referenced in this record:
An auto-tuning framework for parallel multicore stencil computations
conference, April 2010
- Kamil, Shoaib; Chan, Cy; Oliker, Leonid
- 2010 IEEE International Symposium on Parallel & Distributed Processing (IPDPS)
High-performance code generation for stencil computations on GPU architectures
conference, January 2012
- Holewinski, Justin; Pouchet, Louis-Noël; Sadayappan, P.
- Proceedings of the 26th ACM international conference on Supercomputing - ICS '12
Mint: realizing CUDA performance in 3D stencil methods with annotated C
conference, January 2011
- Unat, Didem; Cai, Xing; Baden, Scott B.
- Proceedings of the international conference on Supercomputing - ICS '11
A Survey of CPU-GPU Heterogeneous Computing Techniques
journal, July 2015
- Mittal, Sparsh; Vetter, Jeffrey S.
- ACM Computing Surveys, Vol. 47, Issue 4
CPU+GPU Programming of Stencil Computations for Resource-Efficient Use of GPU Clusters
conference, October 2015
- Sourouri, Mohammed; Langguth, Johannes; Spiga, Filippo
- 2015 IEEE 18th International Conference on Computational Science and Engineering (CSE)
Physis: an implicitly parallel programming model for stencil computations on large-scale GPU-accelerated supercomputers
conference, January 2011
- Maruyama, Naoya; Nomura, Tatsuo; Sato, Kento
- Proceedings of 2011 International Conference for High Performance Computing, Networking, Storage and Analysis on - SC '11
Halide: a language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines
conference, January 2013
- Ragan-Kelley, Jonathan; Barnes, Connelly; Adams, Andrew
- Proceedings of the 34th ACM SIGPLAN conference on Programming language design and implementation - PLDI '13
PATUS: A Code Generation and Autotuning Framework for Parallel Iterative Stencil Computations on Modern Microarchitectures
conference, May 2011
- Christen, Matthias; Schenk, Olaf; Burkhart, Helmar
- Distributed Processing Symposium (IPDPS), 2011 IEEE International Parallel & Distributed Processing Symposium
A Study on Balancing Parallelism, Data Locality, and Recomputation in Existing PDE Solvers
conference, November 2014
- Olschanowsky, Catherine; Strout, Michelle Mills; Guzik, Stephen
- SC14: International Conference for High Performance Computing, Networking, Storage and Analysis
Towards automatic translation of OpenMP to MPI
conference, January 2005
- Basumallik, Ayon; Eigenmann, Rudolf
- Proceedings of the 19th annual international conference on Supercomputing - ICS '05
Understanding stencil code performance on multicore architectures
conference, January 2011
- Rahman, Shah M. Faizur; Yi, Qing; Qasem, Apan
- Proceedings of the 8th ACM International Conference on Computing Frontiers - CF '11
Auto-generation and auto-tuning of 3D stencil codes on GPU clusters
conference, January 2012
- Zhang, Yongpeng; Mueller, Frank
- Proceedings of the Tenth International Symposium on Code Generation and Optimization - CHO '12
Early evaluation of directive-based GPU programming models for productive exascale computing
conference, November 2012
- Lee, Seyong; Vetter, Jeffrey S.
- 2012 SC - International Conference for High Performance Computing, Networking, Storage and Analysis, 2012 International Conference for High Performance Computing, Networking, Storage and Analysis
Abstract Machine Models and Proxy Architectures for Exascale Computing
conference, November 2014
- Ang, J. A.; Barrett, R. F.; Benner, R. E.
- 2014 Hardware-Software Co-Design for High Performance Computing (Co-HPC)
Distributed memory code generation for mixed Irregular/Regular computations
conference, January 2015
- Ravishankar, Mahesh; Dathathri, Roshan; Elango, Venmugil
- Proceedings of the 20th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming - PPoPP 2015
PARTANS: An autotuning framework for stencil computation on multi-GPU systems
journal, January 2013
- Lutz, Thibaut; Fensch, Christian; Cole, Murray
- ACM Transactions on Architecture and Code Optimization, Vol. 9, Issue 4
Tuned and wildly asynchronous stencil kernels for hybrid CPU/GPU systems
conference, January 2009
- Venkatasubramanian, Sundaresan; Vuduc, Richard W.; none, none
- Proceedings of the 23rd international conference on Conference on Supercomputing - ICS '09
OpenMPC: Extended OpenMP Programming and Tuning for GPUs
conference, November 2010
- Lee, Seyong; Eigenmann, Rudolf
- 2010 SC - International Conference for High Performance Computing, Networking, Storage and Analysis, 2010 ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis
High Performance Stencil Code Algorithms for GPGPUs
journal, January 2011
- Schäfer, Andreas; Fey, Dietmar
- Procedia Computer Science, Vol. 4
STELLA: a domain-specific tool for structured grid methods in weather and climate models
conference, January 2015
- Gysi, Tobias; Osuna, Carlos; Fuhrer, Oliver
- Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis on - SC '15
Peta-scale phase-field simulation for dendritic solidification on the TSUBAME 2.0 supercomputer
conference, January 2011
- Shimokawabe, Takashi; Aoki, Takayuki; Takaki, Tomohiro
- Proceedings of 2011 International Conference for High Performance Computing, Networking, Storage and Analysis on - SC '11
SnuCL: an OpenCL framework for heterogeneous CPU/GPU clusters
conference, January 2012
- Kim, Jungwon; Seo, Sangmin; Lee, Jun
- Proceedings of the 26th ACM international conference on Supercomputing - ICS '12
Hybrid Hexagonal/Classical Tiling for GPUs
conference, January 2014
- Grosser, Tobias; Cohen, Albert; Holewinski, Justin
- Proceedings of Annual IEEE/ACM International Symposium on Code Generation and Optimization - CGO '14
Scalable Heterogeneous CPU-GPU Computations for Unstructured Tetrahedral Meshes
journal, July 2015
- Langguth, Johannes; Sourouri, Mohammed; Lines, Glenn Terje
- IEEE Micro, Vol. 35, Issue 4
Optimization of geometric multigrid for emerging multi- and manycore processors
conference, November 2012
- Williams, Samuel; Kalamkar, Dhiraj D.; Singh, Amik
- 2012 SC - International Conference for High Performance Computing, Networking, Storage and Analysis, 2012 International Conference for High Performance Computing, Networking, Storage and Analysis
On the GPU Performance of 3D Stencil Computations Implemented in OpenCL
book, January 2013
- Su, Huayou; Wu, Nan; Wen, Mei
- Lecture Notes in Computer Science
Roofline: an insightful visual performance model for multicore architectures
journal, April 2009
- Williams, Samuel; Waterman, Andrew; Patterson, David
- Communications of the ACM, Vol. 52, Issue 4
Hybridizing S3D into an Exascale application using OpenACC: An approach for moving to multi-petaflops and beyond
conference, November 2012
- Levesque, John M.; Sankaran, Ramanan; Grout, Ray
- 2012 SC - International Conference for High Performance Computing, Networking, Storage and Analysis, 2012 International Conference for High Performance Computing, Networking, Storage and Analysis
High-Productivity Framework on GPU-Rich Supercomputers for Operational Weather Prediction Code ASUCA
conference, November 2014
- Shimokawabe, Takashi; Aoki, Takayuki; Onodera, Naoyuki
- SC14: International Conference for High Performance Computing, Networking, Storage and Analysis
Works referencing / citing this record:
Domain-Specific Multi-Level IR Rewriting for GPU
preprint, January 2020
- Gysi, Tobias; Müller, Christoph; Zinenko, Oleksandr
- arXiv
Figures / Tables found in this record: