Reinforcement learning based schemes to manage client activities in large distributed control systems
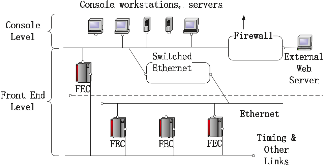
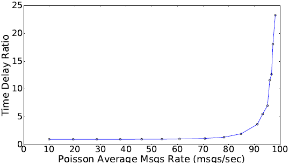
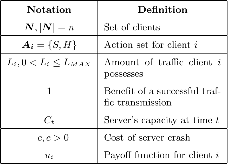
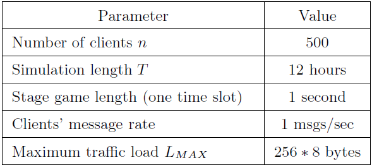
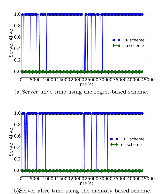
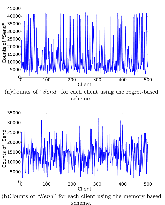
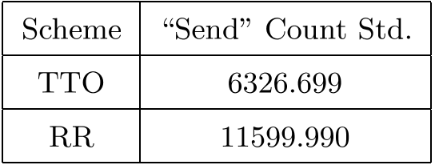
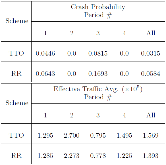
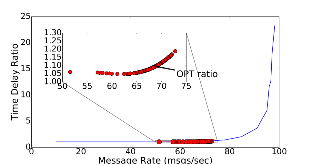
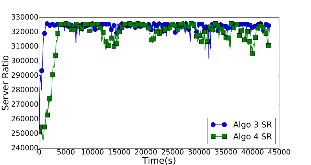
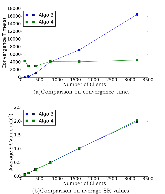
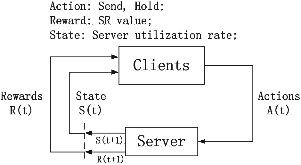
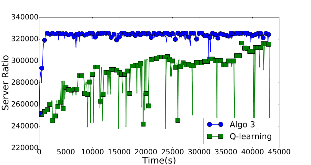
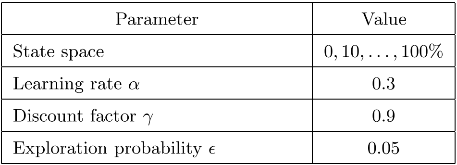
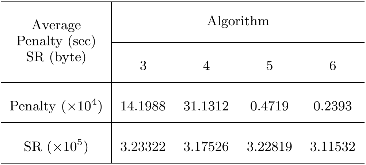
Large distributed control systems typically can be modeled by a hierarchical structure with two physical layers: console level computers (CLCs) layer and front end computers (FECs) layer. The control system of the Relativistic Heavy Ion Collider (RHIC) at Brookhaven National Laboratory (BNL) consists of more than 500 FECs, each acting as a server providing services to a large number of clients. Hence the interactions between the server and its clients become crucial to the overall system performance. There are different scenarios of the interactions. For instance, there are cases where the server has a limited processing ability and is queried by a large number of clients. Such cases can put a bottleneck in the system, as heavy traffic can slow down or even crash a system, making it momentarily unresponsive. Also, there are cases where the server has adequate ability to process all the traffic from its clients. We pursue different goals in those cases. For the first case, we would like to manage clients’ activities so that their requests are processed by the server as much as possible and the server remains operational. For the second case, we would like to explore an operation point at which the server’s resources get utilized efficiently. Moreover, we consider a real-world time constraint to the above case. The time constraint states that clients expect the responses from the server within a time window. In this work, we analyze those cases from a game theory perspective. We model the underlying interactions as a repeated game between clients, which is carried out in discrete time slots. For clients’ activity management, we apply a reinforcement learning procedure as a baseline to regulate clients’ behaviors. Then we propose a memory scheme to improve its performance. Next, depending on different scenarios, we design corresponding reward functions to stimulate clients in a proper way so that they can learn to optimize different goals. Through extensive simulations, we show that first, the memory structure improves the learning ability of the baseline procedure significantly. Second, by applying appropriate reward functions, clients’ activities can be effectively managed to achieve different optimization goals.
- Research Organization:
- Brookhaven National Lab. (BNL), Upton, NY (United States); Stony Brook Univ., NY (United States)
- Sponsoring Organization:
- USDOE; National Science Foundation (NSF)
- Grant/Contract Number:
- SC0012704; 1553385
- OSTI ID:
- 1489305
- Alternate ID(s):
- OSTI ID: 1491685
- Report Number(s):
- BNL-210905-2019-JAAM; PRABCJ; 014601
- Journal Information:
- Physical Review Accelerators and Beams, Journal Name: Physical Review Accelerators and Beams Vol. 22 Journal Issue: 1; ISSN 2469-9888
- Publisher:
- American Physical SocietyCopyright Statement
- Country of Publication:
- United States
- Language:
- English
Web of Science




Similar Records
NSLS-II HIGH LEVEL APPLICATION INFRASTRUCTURE AND CLIENT API DESIGN
Austin Sustainable and Holistic Integration of Energy Storage and Solar PV [Austin SHINES]. Final Report, Version 2